單篇文本資料評估
使用方法與詳細資料介紹「單篇文本分析」功能說明
一、目的
以世界華語之系統跨域角度,分析單篇文本在不同區域系統中各知識點,如:漢字、詞彙之等級分布,以及繁體漢字筆劃統計分析。 本功能透過單一表單可看出該文本在不同區域系統的語言知識點的分布,進而得見其差異與轉換的可能。
二、具體功能項目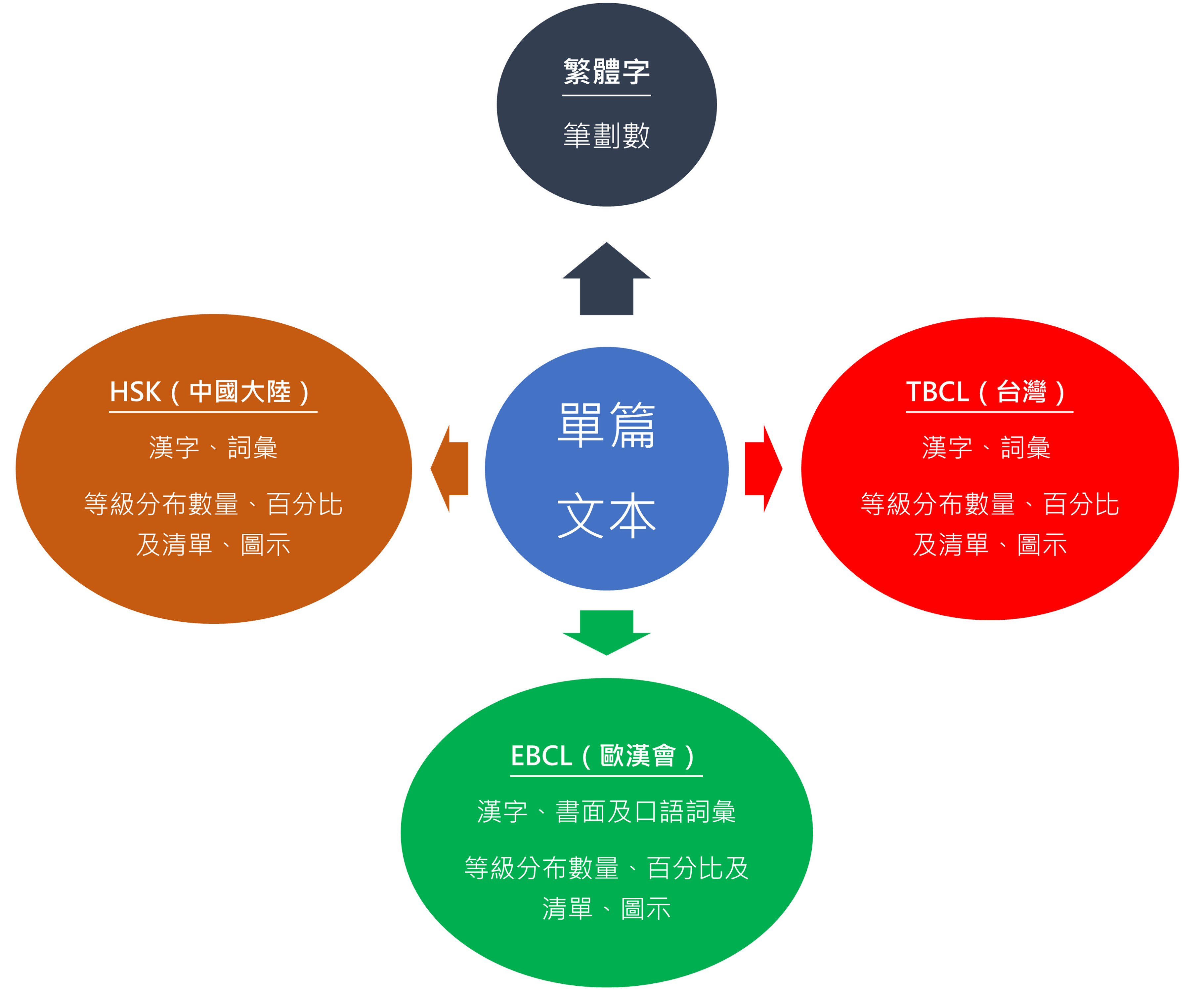
三、本功能依據之標準及版本
-
- 台灣——臺灣華語文能力基準(TBCL,2023)。
- 大陸——國際中文教育中文水平等級標準(GF0025-2021,2021,本網站仍簡稱HSK)。
- 歐洲——歐洲漢語能力基準項目(EBCL,2018)。 (僅限A1、A2)。
- 繁體漢字筆劃——台灣「國語標準字體筆順學習網」; 部分缺漏字並從:台灣「教育部重編國語辭典修訂本」(網路版)補入。
四、操作方法
(一)本功能可以有兩種方法進行:
-
-
- 以檔案形式(txt-純文字檔)上傳。
- 以「複製—貼上」方式上傳。
-
必須注意的是,本系統有防按錯設計,每篇分析完畢後,必須將瀏覽器按「重新整理」後,才能分析下一篇。
(二)操作具體流程:
首先,功能操作區域在瀏覽器視窗左邊1/3部分,如下圖紅色框所示;右邊2/3部分為結果顯示及下載區。

接下來,在左邊紅框區域,可選擇兩種方式:「檔案形式」或「複製—貼上」,將目標文本上傳:
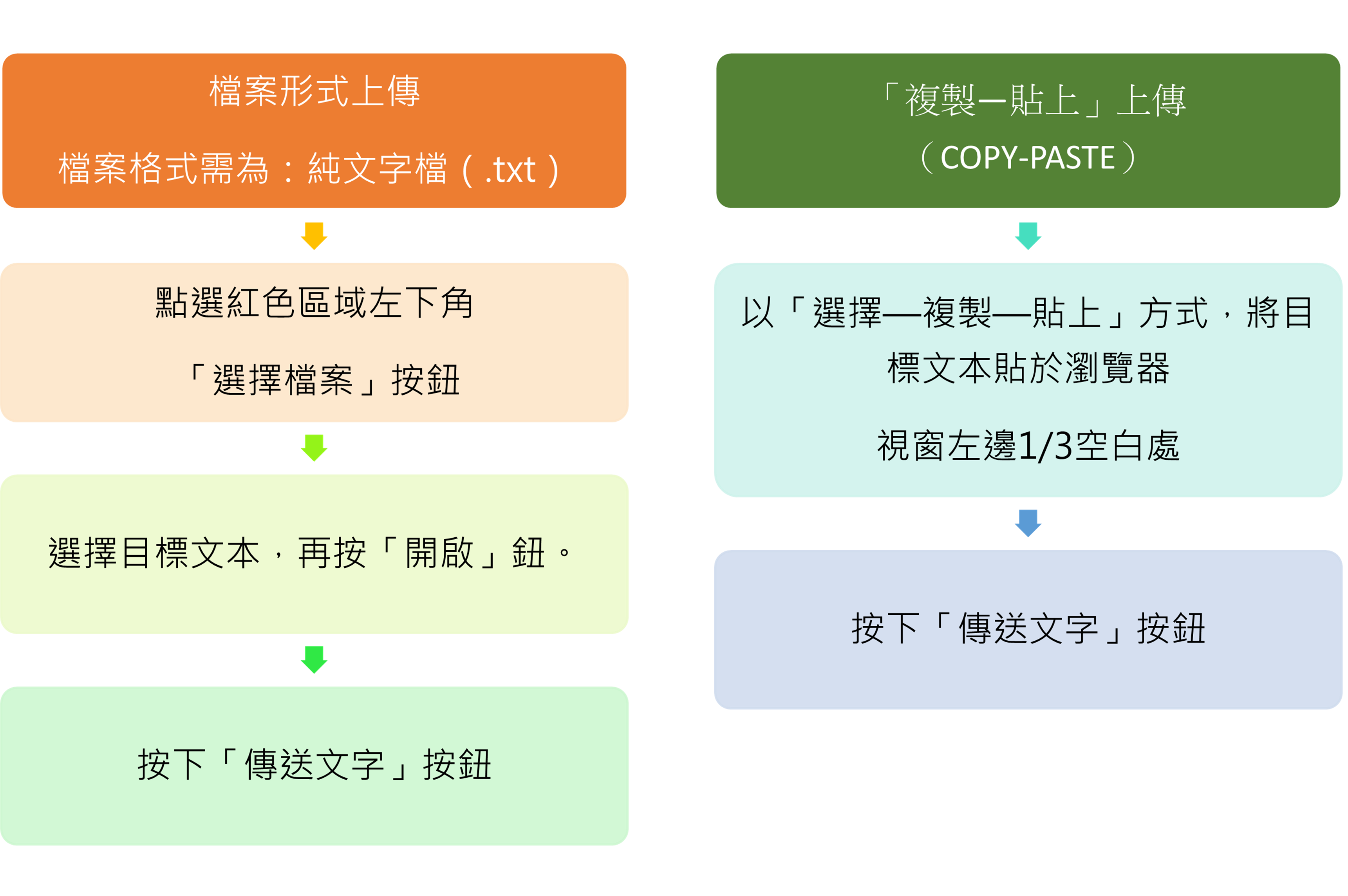


約20-50秒後,即會回傳結果。
五、顯示結果說明
各區域知識點之分析結果主要分成三個部分,如下圖所示
(一)區域知識點之各級數量及百分比

(二)清單下載,格式為txt(純文字)檔,可下載儲存,其內容如下圖所示:

上圖即為文本在TBCL 1-7級詞的詞彙出現清單。
(三)圖示功能,將該文本之知識點依不同顏色將初級—中級—高級加以標注,以期有助於觀察。此圖示功能在點選下載後為excel格式,打開即可顯示,其結果如下:

上述的綠色字即代表該篇文本之詞彙為初級(TBCL 1-3級),藍色字代表中級(TBCL 4-5級),紅色字代表高級(TBCL 6-7級);黑色字則為未收入詞。
六、補充說明:
(一)漢字筆劃及漢字等級
各自依據區域公布之標準所收字進行統計。漢字筆劃之未收字,則以人工方式擴充詞單進行。
(二)詞彙等級
詞彙等級基本上係依據斷詞結果,對各區域系統之詞彙等級內容進行分級統計。
具體來說,本系統之詞彙等級補入不少詞綴、類詞綴及短語,其統計相對漢字筆劃、漢字等級要為複雜。主要是因為文本分析詞彙時,涉及斷詞系統本身之功能,以及詞表本身所收詞彙間存在不一致情形。以台灣TBCL為例,所收詞彙不僅為詞彙,還包括部分短語以及詞綴、類詞綴之詞語,前者的短語如:「開車」、「揭開」、「張開」、「敞開」、「不見了」皆收入詞單;後者如:「北」、「東」等方位詞以及衍生出來的「北部」,以及「法國人」、「外國人」等類詞綴也收入詞單。
後者的情況——衍生的詞綴、類詞綴在TBCL中未直接列入詞表,而是另行獨立之詞單列出。此一方式以閱讀角度來說可以避免大量的詞綴、類詞綴摻入詞彙等級詞單而可能造成對一般詞彙蒐尋判斷的干擾。然而就文本分析詞彙等級而言,則要盡量達到全國覆蓋的目標,因此本系統以補入詞綴、類詞綴方式進行,以求文本詞彙等級分析之全面性。例如:上述「北」、「東」等方位詞收入2級詞,並在2+等級收入「北部」,但未收入「東部」、「南部」等詞,本系統皆依據此一現象擴充收入統計,並將「東部」、「南部」收入2+等級詞。
前者的情況較為複雜。一方面涉及什麼短語要收入統計的判定問題,一方面也涉及斷詞系統本身(如:Ckiptagger),也可能將短語斷為一個詞。從詞單的角度來說,「開車」、「開飛機」應屬同類,而「開車」收入詞單,「開飛機」未收入,則依此現象,似應將此類型的短語收入統計。「打開」、「揭開」、「張開」、「敞開」之結構亦應屬述補短語,此類結構若收入詞單,則其他相關結構亦或應收入。而從斷詞系統來說,現有中文繁體最佳的斷詞系統為中研院之Ckiptagger / Ckiptransf ormer,其斷詞及詞類標註皆可能出現短語。因此,本系統在以等級分析覆蓋率為上的目標下,皆將斷詞後的短語部分,先將其拆開成的各自的詞彙成分,並各自依該詞彙成分判斷其等級,再選擇其中最高之等級斷定該短語之等級,最後回傳到系統,以斷詞系統輸出的短語型態進行等級之統計與標示。